
前言
最近我的服务器过期了,为了迁移我的博客网站做了许多工作,我不想再续服务器了,域名也打算抛弃,但域名还有半年才到期,且存储桶上还有余额没用。我决定先用hexo做静态站点,移动到存储桶上让域名继续发挥其作用,但域名终究是要抛弃的,于是做了很多准备工作,打算记录一下
移动存储桶
我的cdn和存储桶提供商是七牛云,七牛云的api是兼容s3的,我打算将存储桶移到cloudflare r2上,选用其的原因是,cloudflare r2提供了免费额度,对于普通用户是免费的
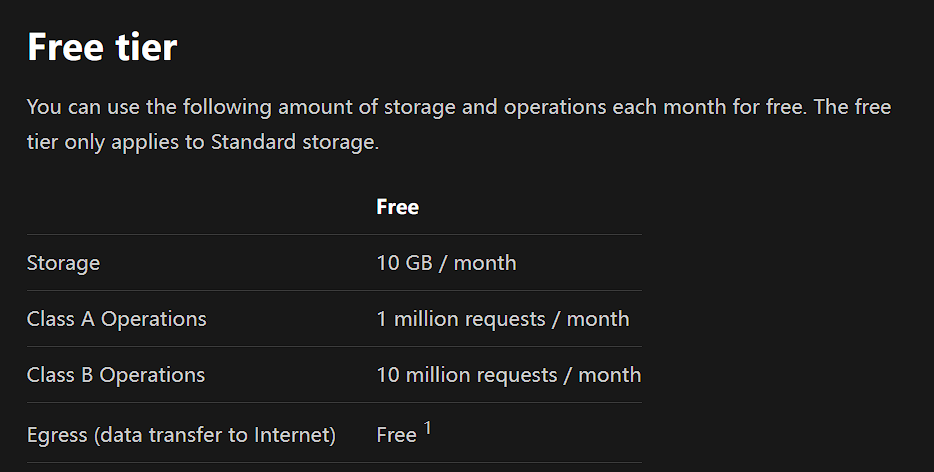
可以见图,Class A Operations 为 写 操作, Class B Operations 为读操作
不管哪个操作都是百万级的,可以说已经是免费了,作图床是绰绰有余的
接下来是迁移方案,cloudflare R2提供了S3 api和自带的迁移
这里有个问题,自带迁移方案只提供google和aws的存储桶迁移,不支持自定义S3迁移
而我使用的S3 api迁移工具为s3trans
在使用七牛云到aws s3的迁移是没有问题的,但迁移到cloudflare r2 s3 api就会出错,我不太理解什么问题,估计是我最爱的防火墙又发力了
开个玩笑。我的解决方案是先迁移到aws s3,再通过cloudflare自带的迁移存储
使用aws s3作为中转存储桶
创建存储桶
输入一个你喜欢的存储桶名字,然后直接确定即可

记录下你创建的存储桶名称,我这里是bucket-twoonefour
bucketname: bucket-twoonefour
创建api密钥

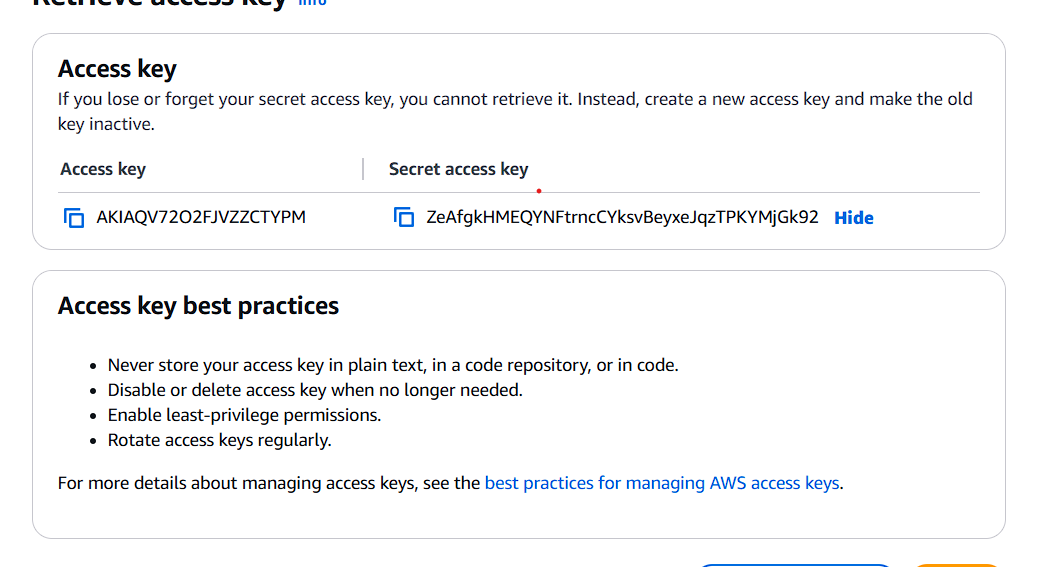
记录下Access key和Secret access key
Access key: AKIAQV72O2FJVZZCTYPM Secret access key: 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
这里给大家看明文,其实我已经删掉了,只是方便演示而已,大家不要动歪脑筋噢(应该也没人看)
接下来是七牛云的S3 api
根据文档
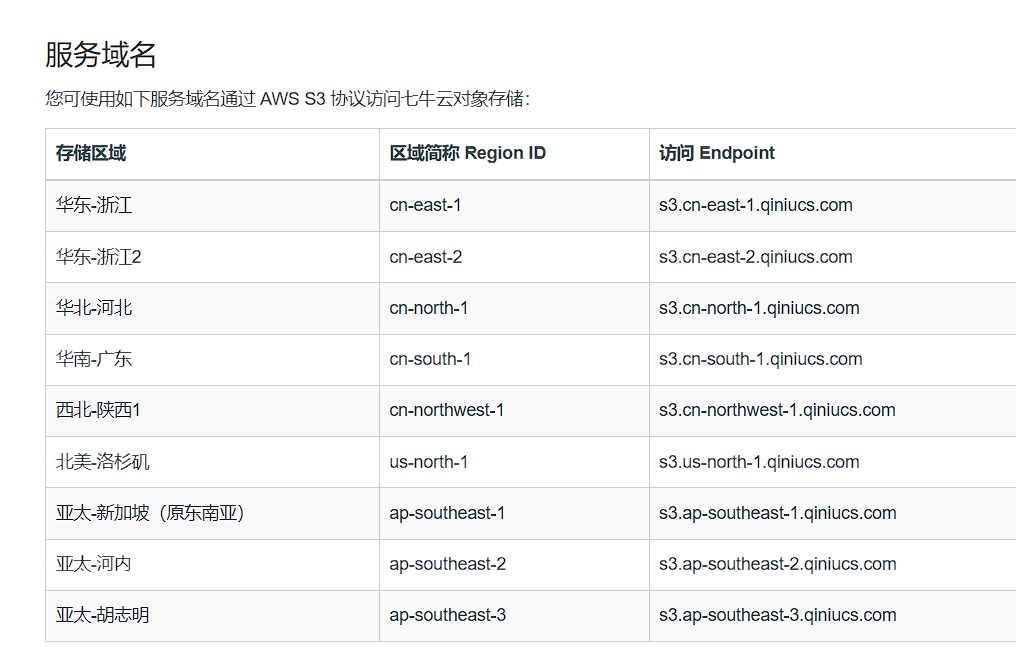 记录下这个endpoint,我这里存储桶区域是
记录下这个endpoint,我这里存储桶区域是华东-浙江

endpoint: s3.cn-east-1.qiniucs.com region: cn-east-1 bucketname: pursuebucket
使用s3trans迁移七牛云存储桶至aws s3
s3trans这里可以获取windows版本的s3trans,但没有linux的,我这里也摆一个我编译好的linux x64版本下载
首先编辑credentials文件
windows位于 %USERPROFILE%/.aws/credentials
linux位于~/.aws/credentials
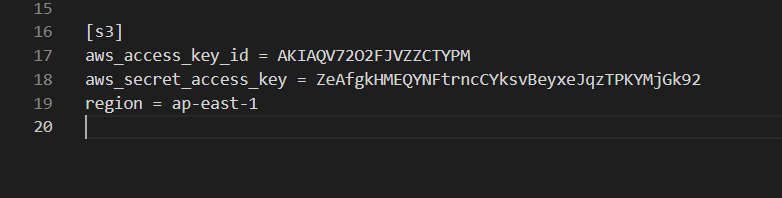
这个region可以从刚才创建s3的地方看到
可以看到是ap-east-1,如果你是别的区域可以自行修改
同理七牛云的key也可以这样获取
AK就是Access key
Sk就是Access secret key
windows操作
打开s3_upload.exe
第一次打开是这样的
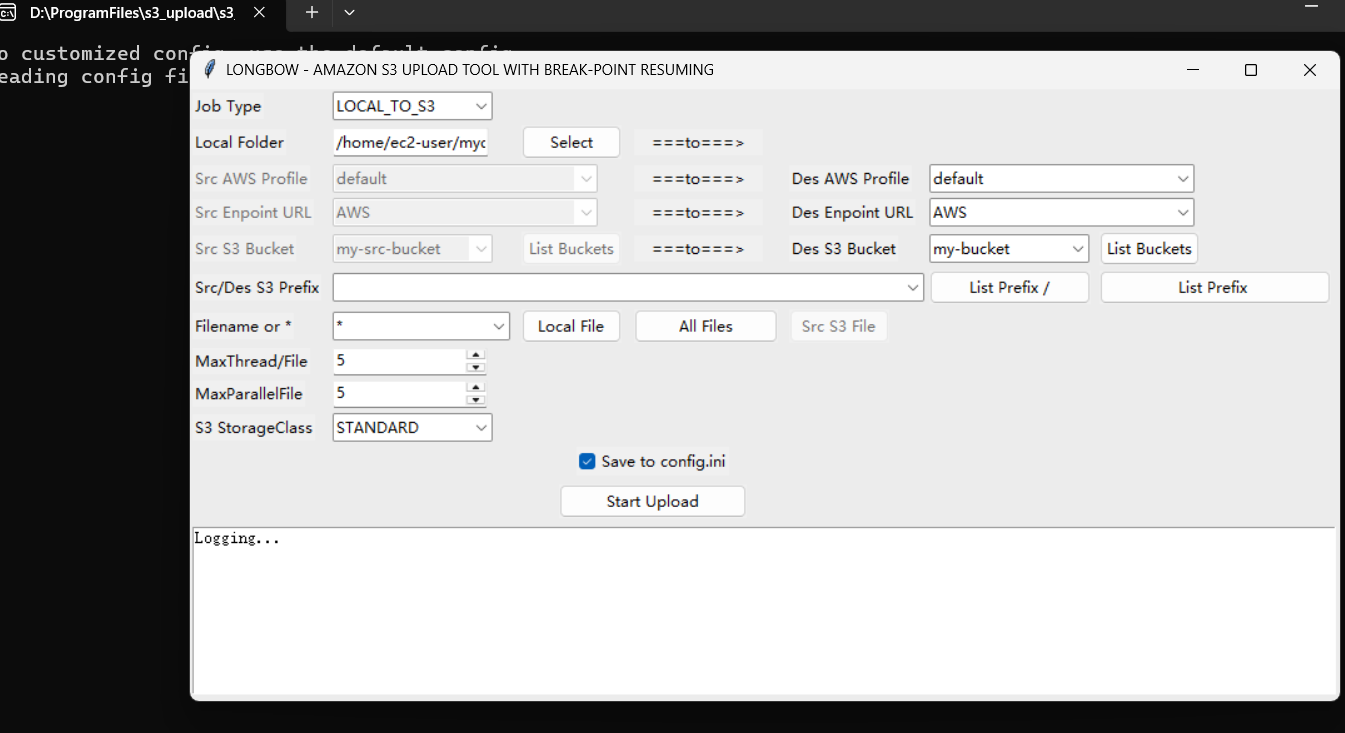
点job type切换成S3_TO_S3
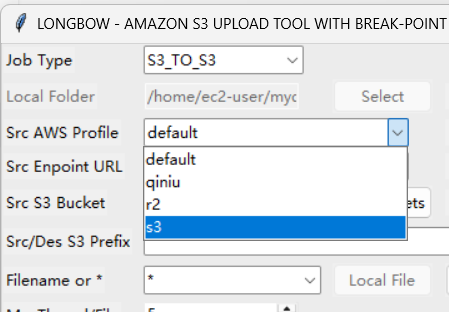
然后aws profile选择刚才上一步填写的s3
如果没问题的话点List Buckets按钮就可以看到自己的存储桶了

同理配置右边
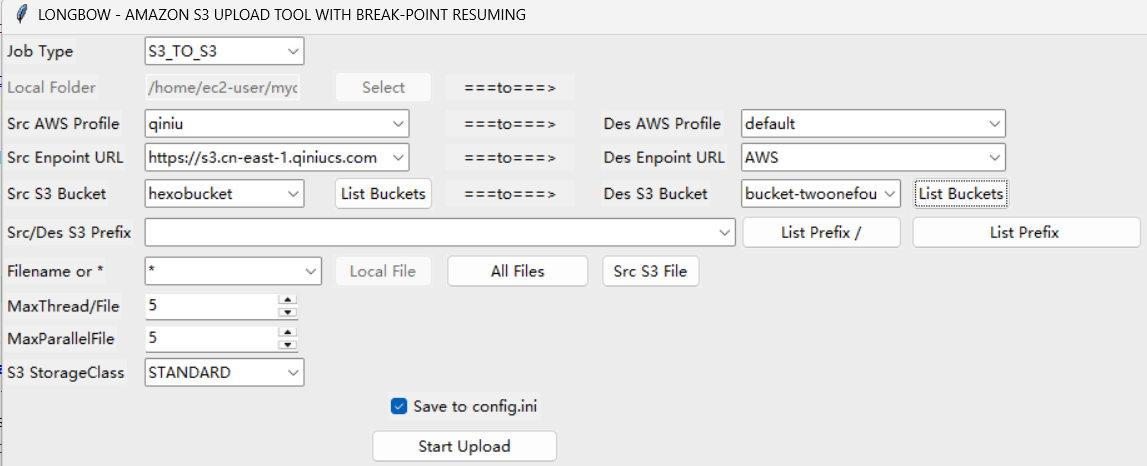
我上面写反了,应该是七牛迁移到aws,左边迁移到右边,大家明白就行,不要学我
这里需要注意的是七牛并没有被这个工具加入endpoint url,需要自己改一下,改成上面获取的endpoint url,我这里的情况是https://s3.cn-east-1.qiniucs.com,请自己按需配置,不要照抄
然后点start upload就迁移完成了
linux操作
我这里就直接给命令了, 应该是可以看得懂命令是啥意思的
|
|
至此迁移到中转aws存储桶结束
使用cloudflare r2自带的迁移
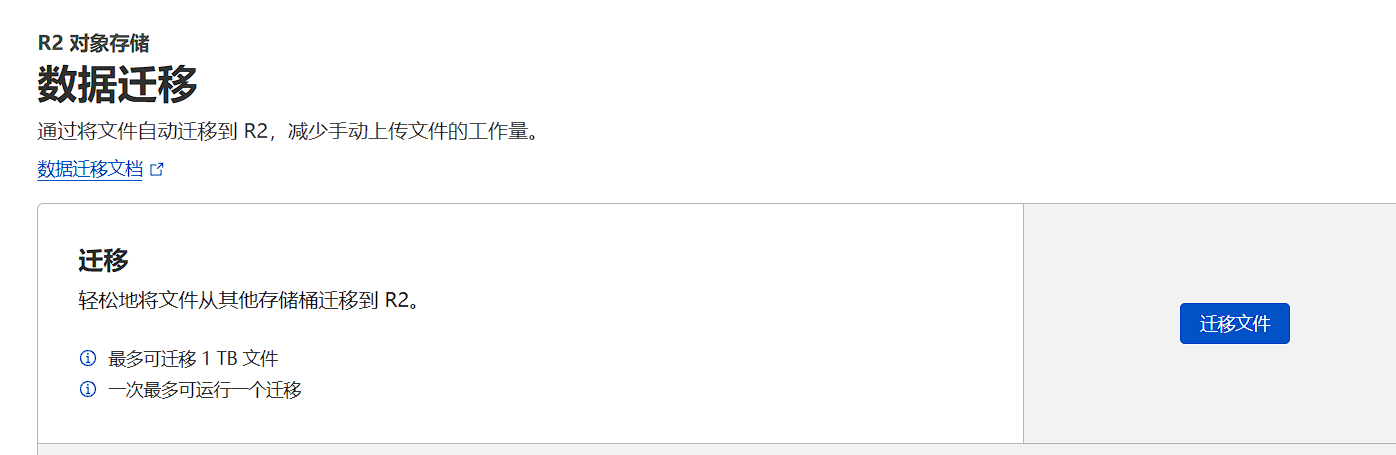
点击迁移文件
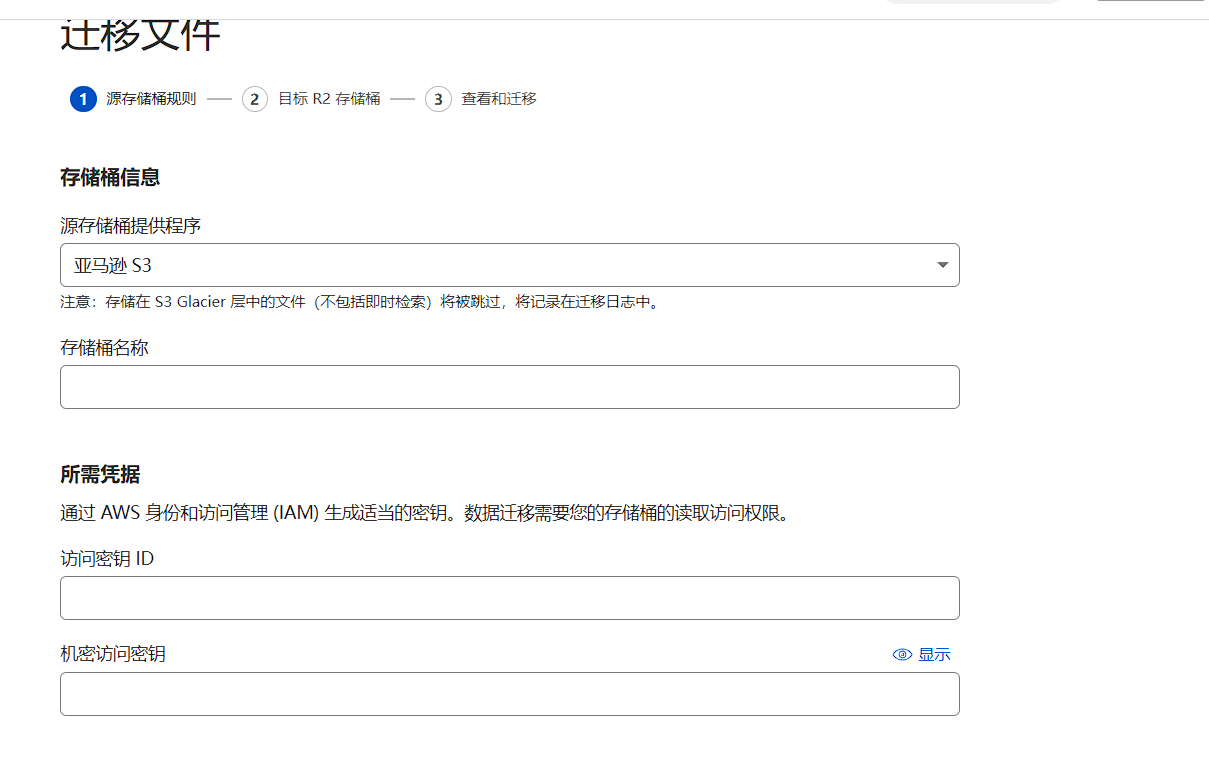
照着输入密钥id和密钥即可

这个路径可以自己决定,也可以不选。我这边是不全部迁移就填了路径
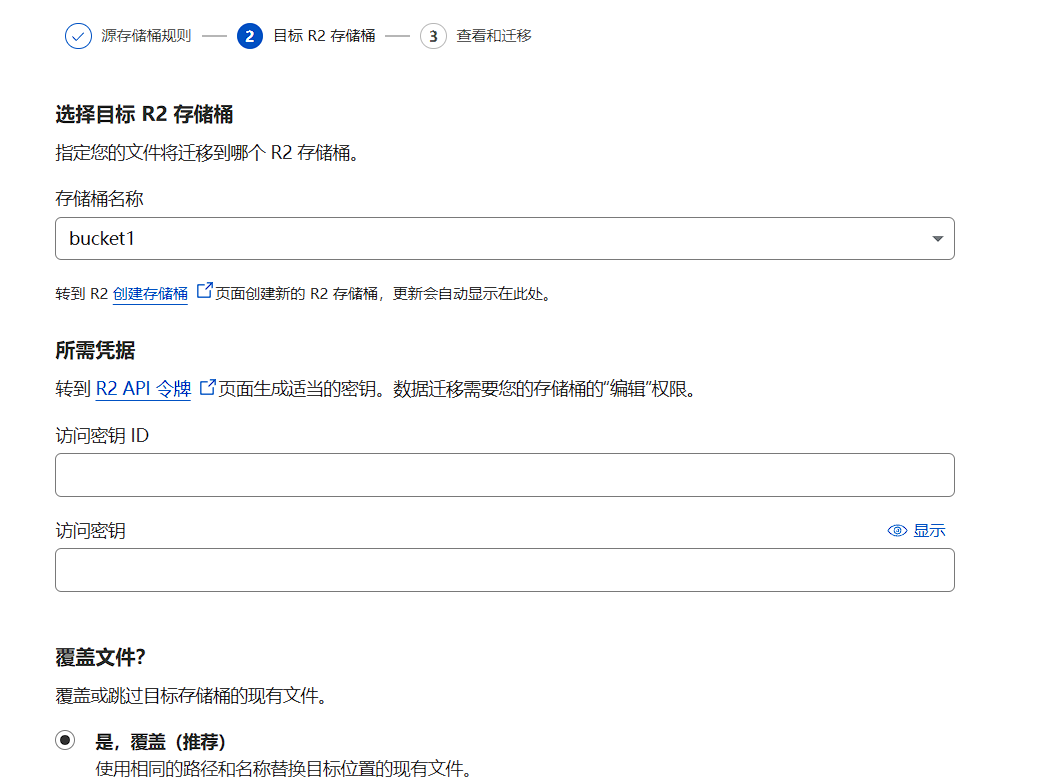
这里选择自己的r2存储桶,填上cloudflare的访问密钥id即可,获取密钥id和访问密钥和之前的获取s3 api密钥流程很相似, 直接略过
点开始即可,迁移部分到此结束,接下来是一些善后处理
七牛云回源r2
我后面是打算只用r2的,但原来的七牛云图床还是要用的
这里就设置了七牛云图床回源cloudflare r2,就不用上传到r2的同时在上传一次七牛云了,配置很简单,只需要打开七牛云的存储桶的空间设置
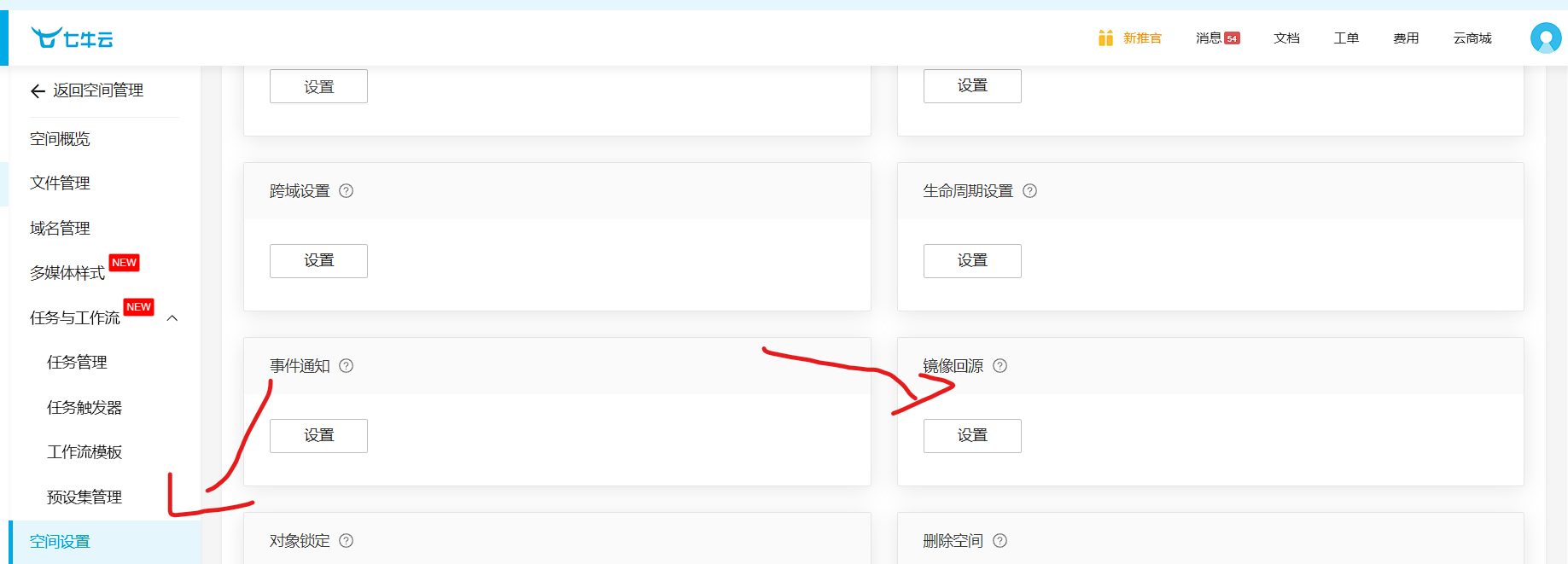
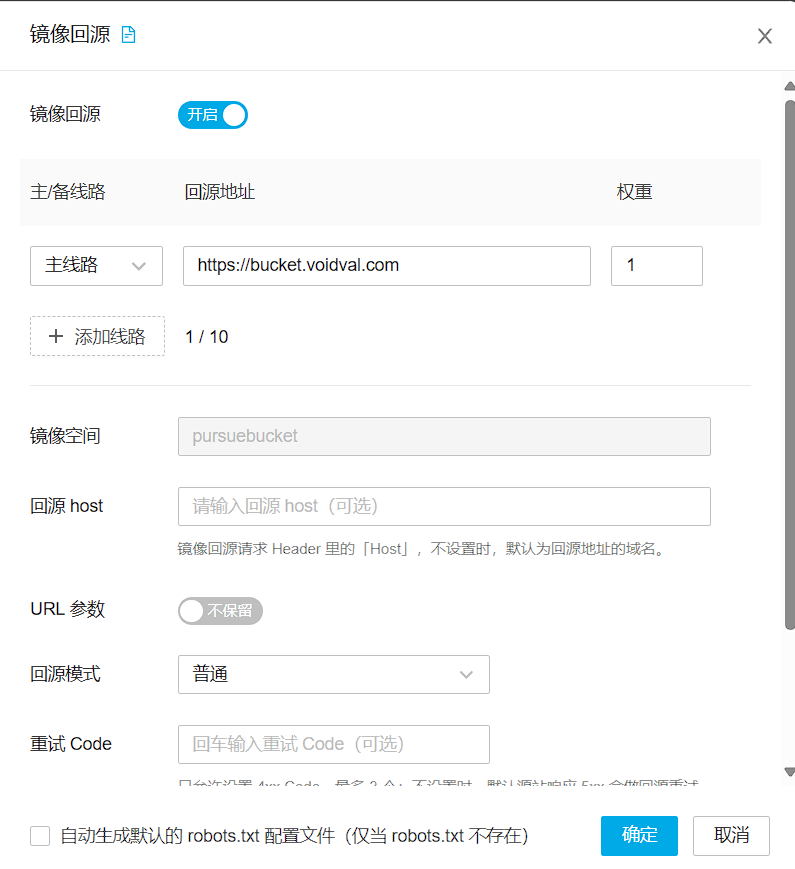
我这里填了r2的回源,逻辑是这样的
访问七牛云 -> 未找到资源 -> 七牛云从源站拉取资源到七牛云存储桶 -> 返回给用户
这样就不需要两边都上传了
迁移halo到hexo,并部署到七牛云作静态资源博客
我这边原来的域名还需要一个博客,但又没有国内服务器作为后端,于是采用hexo做一个静态博客,然后上传到七牛云存储桶,并配置静态资源站点
这样最简单的方式就是需要一个hexo环境,把halo(原来的博客)写的makedown全部导出到hexo目录下的source/_posts/下,然后hexo g,将文件传到七牛云存储桶上即可
但存在如下问题
- 文章的链接不能改变
- 文章发布时需要修改整个存储桶
- 存储桶图床要使用原来的域名
下面我来逐个击破
文章链接不能改变
在hexo中,makedown文章有permalink作为文章的链接路由,只需要添加此句即可,halo的导出文章插件正好支持这一点
ps:必须要选用不会固定permalink的hexo主题,点名hexo-theme-aurora,会绑定permalink: post/:title.html,所以不能使用,我选择的是hexo-theme-butterfly
halo的permalink是archives/:title,如这一篇
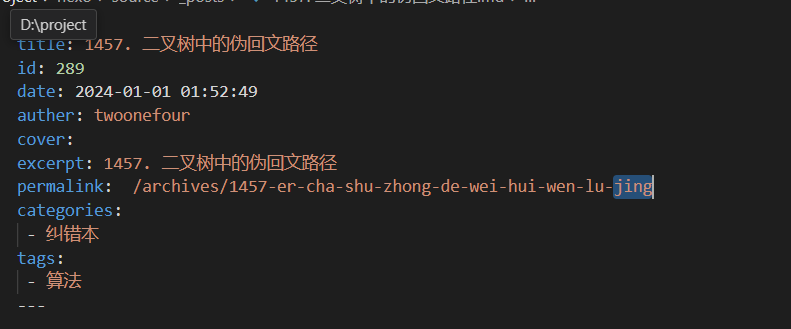
这一篇导出来permalink是/archives/1457-er-cha-shu-zhong-de-wei-hui-wen-lu-jing
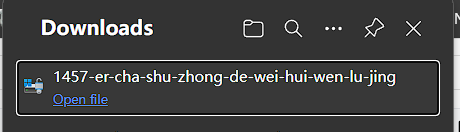
若不修改的话,hexo生成会变成这样的文章

若直接访问这个链接会变成流式文件,访问后不会进入文章,而是会变成下载文件,这是我不希望出现的
那么只能这么写permalink
permalink: /archives/1457-er-cha-shu-zhong-de-wei-hui-wen-lu-jing/
在后面添加一个斜杠,hexo会生成archives/1457-er-cha-shu-zhong-de-wei-hui-wen-lu-jing/index.html

如果要批量修改就用sed
|
|
那问题又来了,传到七牛云上,会不会变成访问
archives/1457-er-cha-shu-zhong-de-wei-hui-wen-lu-jing/index.html才可以进入博客而非访问archives/1457-er-cha-shu-zhong-de-wei-hui-wen-lu-jing/
好问题,实际上是不会的,七牛云的静态页面会访问该文件夹下的index.html,而不会发生404 not found
至此第一个问题解决
文章发布时需要修改整个存储桶
首先文章发布我的选择是传到github的仓库,我这里是私有仓库,这样还能蹭一些容器自动发布的功能如vercel和zeabur
首先forkhexo仓库
然后克隆到本地
git clone https://github.com/twoonefour/hexo.git
在发布文章时只需要把文章markdown放到source/_posts,然后git commit -a -m "new post" && git push即可
当然我这里介绍的是部署静态hexo到存储桶上,接着看下文
我写了一个python脚本用于访问七牛云api
根据官方文档有如下流程
pip install qiniu
然后删除所有文件
我这里存储桶中删除所有文件的代码如下
|
|
接下来hexo生成文件再上传,还需要刷新cdn缓存
hexo操作
hexo clean && hexo g
生成了新hexo文件,然后上传到七牛云
这里又用到s3trans, 我这里是vmware的linux服务器,你可以采用其他的上传,比如接着写七牛api上传, 我是懒得写了
s3trans public/ s3://hexobucket –to-endpoint=https://s3.cn-east-1.qiniucs.com –to-profile=qiniu –skip-compare
最后刷新cdn缓存
|
|
刷新一下缓存,这里需要刷新目录下的index.html和目录下所有的文件
最终发布的执行代码如下
windows本地放入文章后,build.bat
|
|
服务器端脚本
|
|
现在发布文章的流程就变成了:在发布文章时只需要在windows本地把文章markdown放到source/_posts,然后双击build.bat即可
存储桶图床要使用原来的域名
这个问题只需要在文章makedown中使用原来图床的域名
后面等到域名过期,可以用sed一句话替换文章所有域名
sed -i ’s/pursuecode.cn/pursuecode.cn/g’ *.md
只要你图床存储桶的结构不变就可以。我这里是经过上面步骤迁移的,所以肯定是不变的
我碰到的问题是:当halo要所有文章全都修改文章的图床域名时就要一个个修改,因为涉及到数据库,文章并不是以markdown存储的
我在halo的github上找到了答案
至此所有问题都解决了,完结撒花!